外观
问题合集
vim时意外退出,恢复流程
使用vim -r恢复
vim -r caixukun.sh提示
执行上一步时需要回车一下,进入vim中wq保存退出,此时.caixukun.sh.swp文件内容会同步到caixukun.sh
删除swp文件
rm -rf .caixukun.sh.swp使用find配合exec时报错:find missing argument to '-exec'
root@VM-0-4-ubuntu:/opt/mysql/mysql-backup# find /opt/mysql/mysql-backup/* -mtime +3 -name "*.gz" -exec rm -rf {};
find: missing argument to `-exec'我这里的解决方案是加一个\
find /opt/mysql/mysql-backup/* -mtime +3 -name "*.gz" -exec rm -rf {} \;注
{}前后需要加空格
执行curl时报错
curl: symbol lookup error: curl: undefined symbol: curl_easy_nextheader解决方案:
ldconfigumount时报错target is busy.
[root@ecs-79cf-0708514 downloads]# umount /downloads/
umount: /downloads: target is busy.
(In some cases useful info about processes that use
the device is found by lsof(8) or fuser(1))解决方案: 安装fuser工具
yum install psmisc.x86_64 -y使用fuser定位进程信息
[root@ecs-79cf-0708514 downloads]# fuser -m -u /downloads
/downloads: 5701c(root) 5779c(root)相关信息
在例子中,使用了-m和-u选项,用来查找所有正在使用/downloads 的所有进程的PID,以及该进程的OWNER,如5701c(root),其中5701是进程PID,root是该进程的OWNER。
查看进程使用的文件
[root@ecs-79cf-0708514 downloads]# ls -al /proc/5701/fd/
total 0
dr-x------ 2 root root 0 Oct 8 10:17 .
dr-xr-xr-x 9 root root 0 Oct 8 10:17 ..
lrwx------ 1 root root 64 Oct 8 10:17 0 -> /dev/pts/0
lrwx------ 1 root root 64 Oct 8 10:17 1 -> /dev/pts/0
lrwx------ 1 root root 64 Oct 8 10:17 2 -> /dev/pts/0
lrwx------ 1 root root 64 Oct 8 10:53 255 -> /dev/pts/0
[root@ecs-79cf-0708514 downloads]# ls -al /proc/5779/fd/
total 0
dr-x------ 2 root root 0 Oct 8 10:40 .
dr-xr-xr-x 9 root root 0 Oct 8 10:40 ..
lrwx------ 1 root root 64 Oct 8 10:40 0 -> /dev/pts/1
lrwx------ 1 root root 64 Oct 8 10:40 1 -> /dev/pts/1
lrwx------ 1 root root 64 Oct 8 10:40 2 -> /dev/pts/1
lrwx------ 1 root root 64 Oct 8 10:53 255 -> /dev/pts/1通过ppid查看进程
[root@ecs-79cf-0708514 downloads]# ps --ppid 5779
PID TTY TIME CMD
5856 pts/1 00:00:00 ps
[root@ecs-79cf-0708514 downloads]# ps --ppid 5701
PID TTY TIME CMDkill进程
注意
可能会kill掉当前终端
[root@ecs-79cf-0708514 downloads]# kill -9 5701
[root@ecs-79cf-0708514 downloads]# kill -9 5779再次尝试umount
[root@ecs-79cf-0708514 ~]# umount /downloads/
[root@ecs-79cf-0708514 ~]#成功
创建pod或者services的时候报错the provided range does not match the current range
修改kube-apiserver.yaml文件
相关信息
添加- --service-node-port-range=1-65535
vim /etc/kubernetes/manifests/kube-apiserver.yaml重启kubelet
systemctl daemon-reload
systemctl restart kubelet提示
如果你之前已经修改了,并且当时起了作用,下次用的时候发现失效了,那就先把那一行注释掉,重启kubelet,稍等一会然后把注释去掉再重启kubelet
Pod无法连通集群外的服务(可以ping通。不知道是不是操作方法有问题,telnet也是可以通的。)
相关信息
我这里外部服务以Mongo为例。操作系统为:Centos7.9
查看iptables规则,观察Chain INPUT和Chain OUTPUT
iptables -L如果不是ACCEPT,那就执行以下命令,放通所有流量
iptables -P INPUT ACCEPT
iptables -P OUTPUT ACCEPT如果执行如上命令还是不行的话,那就要设置KUBE-FORWARD规则
iptables -I KUBE-FORWARD -p tcp --sport 27017 -j ACCEPT
iptables -I KUBE-FORWARD -p tcp --dport 27017 -j ACCEPT注
添加完成后必须快速验证,因为KUBE-FORWARD很快就会重置,如果此方法还是不行的话,那本篇文章就帮不到你了
如果添加KUBE-FORWARD规则可行的话,那就可以试着配置Firewall来实现转发,因为配置KUBE-FORWARD的规则存在不了多久就会被Kube-Proxy重置,感兴趣的可以去Google一下:Kubernetes Iptables
安装Firewall
yum install firewalld -y配置Firewalld规则
TCP: firewall-cmd --permanent --add-port=27017/tcp
UDP: firewall-cmd --permanent --add-port=27017/udp开启Firewall并设置开机自动启动
systemctl start firewalld
systemctl enable firewalld配置ssh免密登录时报错
配置ssh免密时报错
[root@jenkins .ssh]# ssh-copy-id root@150.158.xxx.xxx
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: ERROR: @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
ERROR: @ WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! @
ERROR: @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
ERROR: IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY!
ERROR: Someone could be eavesdropping on you right now (man-in-the-middle attack)!
ERROR: It is also possible that a host key has just been changed.
ERROR: The fingerprint for the ECDSA key sent by the remote host is
ERROR: SHA256:Ly2qQIR34xDh1mAqLxW6PA28I7DX4TGOsMRZTIAKlpE.
ERROR: Please contact your system administrator.
ERROR: Add correct host key in /root/.ssh/known_hosts to get rid of this message.
ERROR: Offending ECDSA key in /root/.ssh/known_hosts:10
ERROR: ECDSA host key for 150.158.x.x has changed and you have requested strict checking.
ERROR: Host key verification failed.解决方案:删除known_hosts文件或者删掉文件内的x.x.x.x访问记录
rm -rf /root/.ssh/known_hosts以master身份加入Kubernetes集群时报错:failed to dial endpoint https://192.168.7.2:2379 with maintenance client: context deadline exceeded
master节点查询etcd相关Pod
kubectl get pod -n kube-system进入etcd Pod
kubectl exec -ti etcd-k8s-master01 -n kube-system sh查询Etcd信息
export ETCDCTL_API=3
etcdctl --cacert="/etc/kubernetes/pki/etcd/ca.crt" --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" member list把出问题的节点删除
etcdctl --cacert="/etc/kubernetes/pki/etcd/ca.crt" --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" member remove 17826e460c060952浏览器访问10080端口时报错
因为某种原因,需要搭一个Nginx暴露五位数端口,当时选择了10080这个端口,服务就绪,本机也暴露10080端口,但是访问浏览器访问10080就是不行,报错ERR_UNSAFE_PORT

后来google了下,发现10080端口作特殊用途,需要换个端口
提示
目前,谷歌浏览器正在阻止端口69、137、161、554、1719、1720、1723、5060、10080、5061和6566上的FTP,HTTP和HTTPS访问。
修改Mysql时区
查看当前时区
show variables like "%time_zone%";修改时区
set global time_zone = '+8:00';
set time_zone = '+8:00';注意
上面两条SQL只是临时修改时区,下次myslq重启就会失效
追加配置项以实现永久修改时区
vim /etc/my.cnf
==================================================================================================================================[mysqld]
default-time_zone = '+8:00'重启Mysql
systemctl stop mysqld.service
systemctl start mysqld.service通过Post方式通过Nginx上传超过10K文件报错404
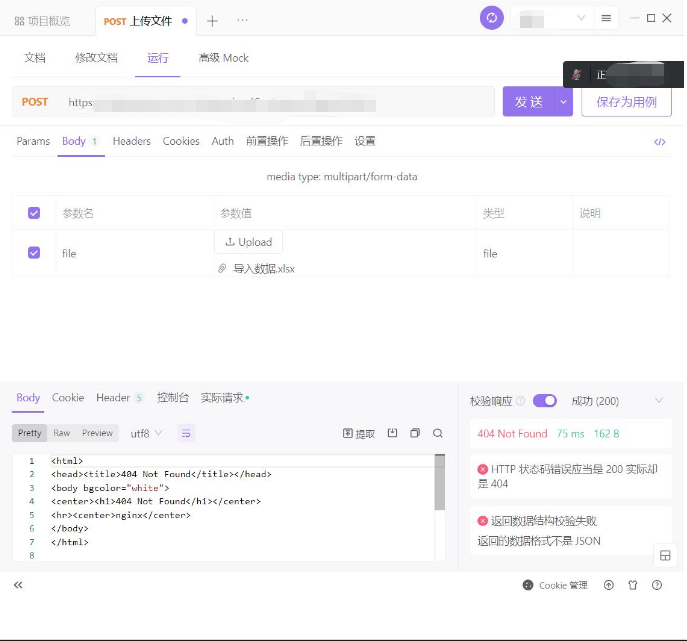
修改位置文件,新增或修改配置项就能解决这个问题
vim /etc/nginx/nginx.conf
==================================================================================================================================
server {
...
...
client_max_body_size xxxm;
client_body_buffer_size xxxm;
...
...
}docker-compose启动容器时报错:Cannot start service touty-ui: OCI runtime create failed: container_linux.go:349: starting container process caused "process_linux.go:319: getting the final child's pid from pipe caused "EOF"": unknown
sysctl -w vm.drop_caches=1docker-compose启动容器时报错:An HTTP request took too long to complete. Retry with --verbose to obtain debug information.If you encounter this issue regularly because of slow network conditions, consider setting COMPOSE_HTTP_TIMEOUT to a higher value (current value: 60.)
相关信息
大概有下面四种方法
- 观察想要up的容器是否在Created状态,可以尝试先删除掉这个容器重新创建
- 重新安装docker-compose
curl -L https://get.daocloud.io/docker/compose/releases/download/1.24.0/docker-compose-`uname -s`-`uname -m` > /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose- 追加COMPOSE_HTTP_TIMEOUT变量,并把值调大
vim /etc/profile
====================================================================================================================================================
export COMPOSE_HTTP_TIMEOUT=500
export DOCKER_CLIENT_TIMEOUT=500
====================================================================================================================================================
source /etc/profile- 删除些许容器
docker-compose 启动 java 容器时报错 library initialization failed - unable to allocate file descriptor table
找到 docker.service 文件,在 ExecStart=/usr/bin/dockerd 后面添加 --default-ulimit nofile=65536:65536 参数
相关信息
service文件一般在 /etc/systemd/system/ 或者 /usr/lib/systemd/system/
不管是docker run或者docker-compose启动一个镜像时:如果你的预期是这个容器开启某个服务或者其他原因,需要这个容器一直在运行,但是实际执行完dockerfile里所写的所有操作就退出
首先要看你的dockerfile是不是最后一条命令或者操作的对象是一个Shell脚本或者其他脚本
如果是的话,以Shell脚本为例,可以在shell脚本的最后一行添加一条tail或者top操作,使这个脚本永远不会结束
操作对象不是脚本文件
可以试着在Docker-Compose文件中添加tty: true配置项
关于Nginx 反向代理 获取客户端访问IP在Kubernetes1.19.x中获取到的IP是内网IP,而不是客户端真实的IP
首先如果确认配置没问题的话,可以通过Access Log来确认,如果Log的IP也是内网IP
确定域名绑定的公网IP,确定这个IP绑定到那个服务器上了,把Nginx Pod调度到绑定公网IP的那台服务器上,然后在Nginx SVC文件中添加[externalTrafficPolicy: Loca]配置 
访问Grafan时报错Origin not allowed
如果你的Grafan做了反向代理,在代理配置文件中添加proxy_set_header Host配置
vim grafna.conf location /grafana {
proxy_set_header Host www.ikun.blog;
proxy_pass http://grafana-service.monitor:3000/grafana;
}重启Grafana
在配置监控Cadvisor时启动报错:Failed to create a Container Manager: mountpoint for cpu not found
修改镜像为gcr.io/cadvisor/cadvisor
cadvisor:
image: gcr.io/cadvisor/cadvisor
container_name: cadvisor
hostname: cadvisor
privileged: true
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /downloads/docker/:/var/lib/docker:ro
- /dev/disk/:/dev/disk:ro
ports:
- "18080:8080"
devices:
- "/dev/kmsg"
restart: always在搭建Kubernetes1.19.0时,安装配置Flannel失败,Node一直处于NotReady状态,检查Kubelet日志发现报错Unable to update cni config: no valid networks found in /etc/cni/net.d
所有Node下载cni插件
wget https://www.ikun.blog/downloads/kubernetes/cni-plugins-linux-amd64-v1.2.0.tgz解压到/opt/cni/bin目录下
cd /opt/cni/bin
cp -r /opt/cni/bin /opt/cni/bin_BAK
rm -rf ./*
tar zxvf cni-plugins-linux-amd64-v1.2.0.tgz
rm -rf cni-plugins-linux-amd64-v1.2.0.tgz所有Node重启Kubelet
systemctl daemon-reload
systemctl restart kubelet重新部署Flannel
kubectl delete -f kube-flannel.yml
kubectl apply -f kube-flannel.yml